

In this section we will go through the first generation techniques.
First generation mitigations ( The Titans)
The first generation's mitigations are focused on detecting or preventing memory corruptions caused in the program. Over course of years, the timeline of these mitigations looks something like this
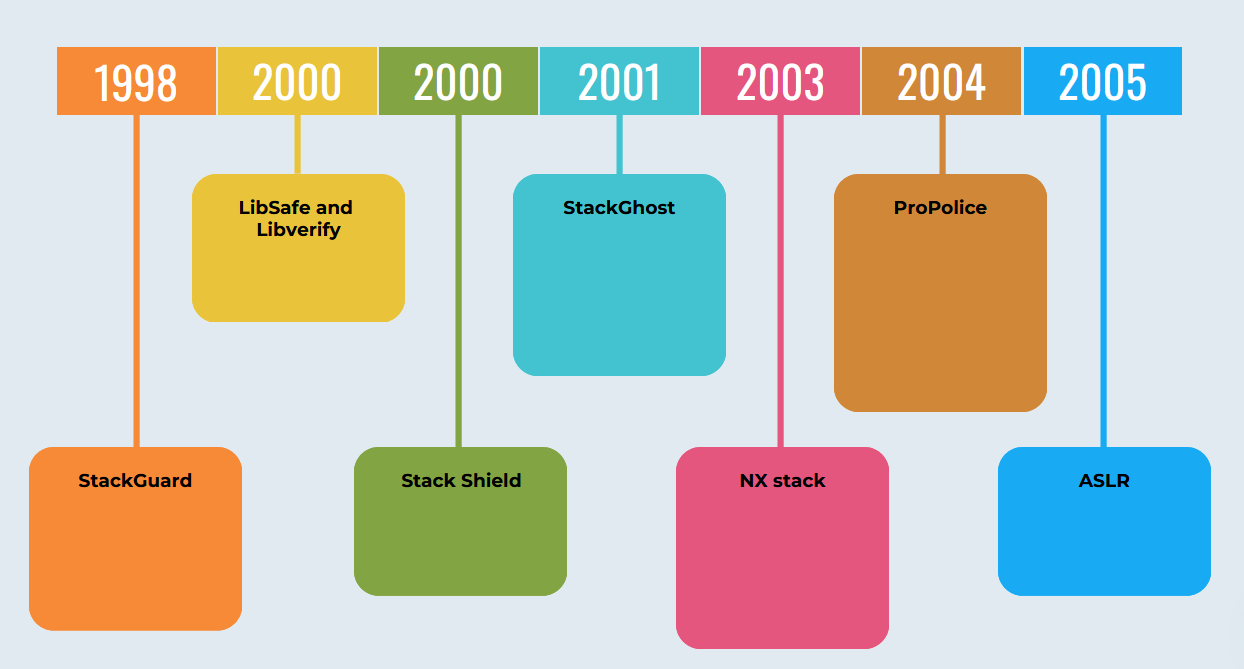
Stack Guard
Stack guard, also referred to as Stack smashing protection, was initially introduced in 1997 as a notable defense mechanism against buffer overflow. This innovation was subsequently integrated into gcc 2.7 in the year 1998. The consumer market was first presented with this safeguard in the Immunix distribution during the same year.
The operating principle of stack guard involves adding a random 8 bytes data (called stack canaries) at the starting of the function stack frame. Upon the function's return, a comparison is made to ascertain whether the canary remains unchanged. In the event of an overflow, the canaries are also altered so as to modify the return address. Upon termination, if it is determined that the canary has been tampered, the program gets terminated.

Let’s take a look at the stack guard implementation in linux.
Stack canary implementation in Linux:
If you compile the above mentioned classic buffer overflow program in any linux distro with parameter -fstack-protector and check the disassembly in IDA, you will see some canary specific check at starting of main function.
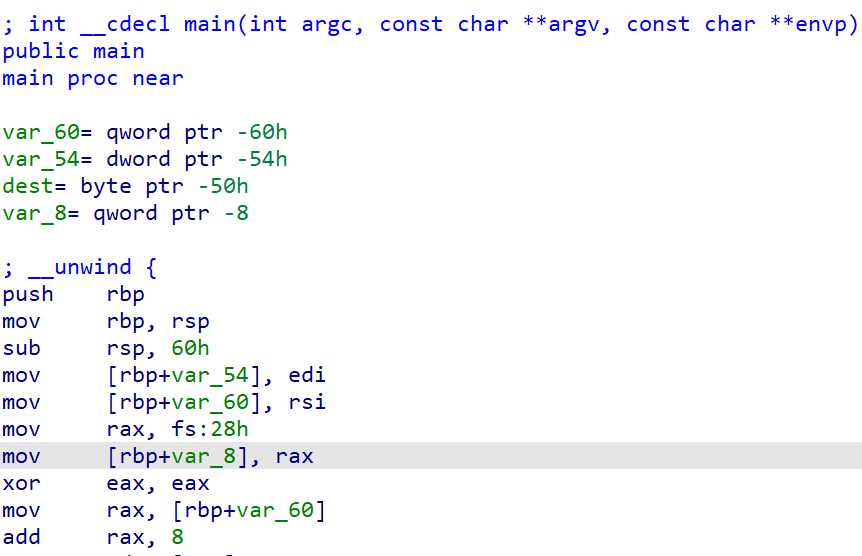
Here fs:[0x28] holds the random 8 byte stack guard value that has been saved to stack (showing as var_8) as the first thing. At the function epilog you will see the following instructions sequence.
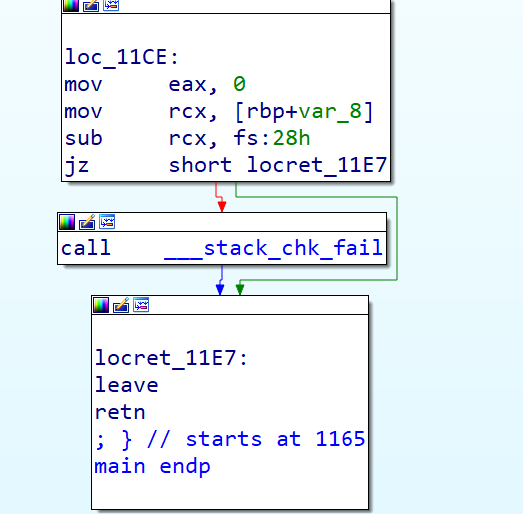
Here the var_8 (which holds the canary value) is moved to rcx and subtracted fs:0x28 from it to check if it’s 0 or not. If it’s not zero, implies the canary value has been modified which cause execution of __stack_chk_fail, that will terminate the program execution.
Note: Use of fs segment in latest x86 linux: The%fssegment register is used to implement the thread pointer. The linear address of the thread pointer is stored at offset 0 relative to the%fssegment register.
On which functions gcc adds stack guards?
From the previously mentioned observations, it can be inferred that the inclusion of stack guard entails the addition of a considerable number of novel instructions to a given function. This, in turn, may result in a slight performance impact. Consequently, compilers such as gcc, or any other compiler for that matter, will only append these stack guard checks to a function if specific prerequisites are satisfied. Thus, the following options are made available within the gcc framework to enable stack guard functionality based on requirement:
- -fstack-protector – Adds stackguard on functions that have a local buffer of 8 bytes or more or functions that call alloca().
- -fstack-protector-strong – Adds stack guard on functions that have local array definitions, or have references to local frame addresses.
- -fstack-protector-all – Adds canary on all functions.
Stack canaries on linux kernel
Stack Canary based protection was introduced in linux kernel 2.6 in 2008. Linux supports following config parameters to define which functions needs canary during build:
- CONFIG_CC_STACKPROTECTOR – Similar to -fstack-protector. Puts canary at starting of function with stack allocation more than 8 bytes.
- CONFIG_CC_STACKPROTECTOR_STRONG – Similar to -fstack-protector-strong.
- CONFIG_CC_STACKPROTECTOR_ALL - Add canary to all function
- CONFIG_CC_STACKPROTECTOR_AUTO – Try to compile the kernel with the best possible option available.
- CONFIG_CC_STACKPROTECTOR_NONE – Build kernel without any stack guard protection.
The instruction sequence will looks like below:
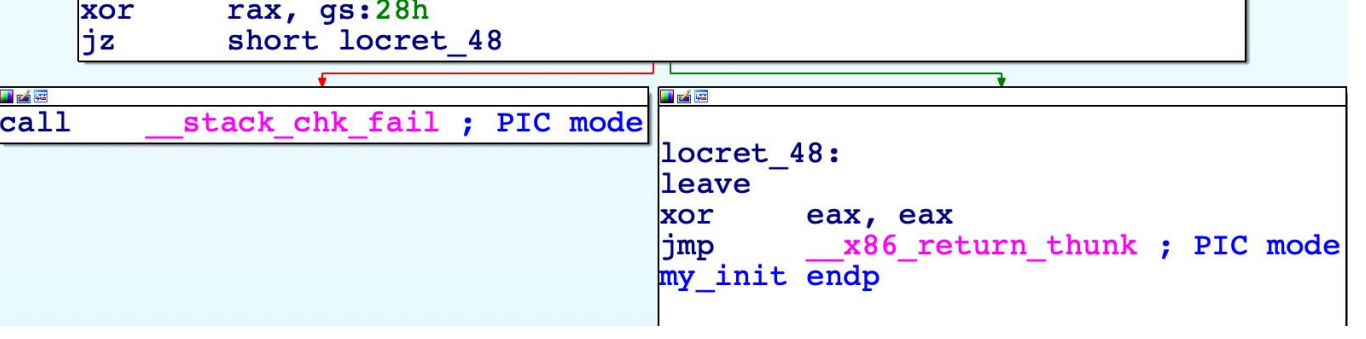
Stack Guard in Windows
Stack guard was introduced in windows in 2003 with the visual studio support for /gs flag.
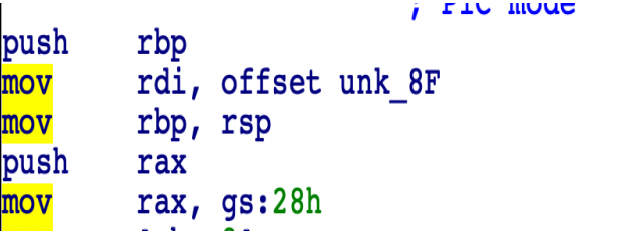
In case of windows you will going to see following instruction set at the function prolog:

In windows, rather than saving the canary directly like linux implementation, it's first xored with base pointer(rbp) and then saved in the stack.Extra xor operation adds a layer of randomization to canary value since the base pointer itself is random on each program execution due to ASLR. Following will be the code you will find on epilog of function:
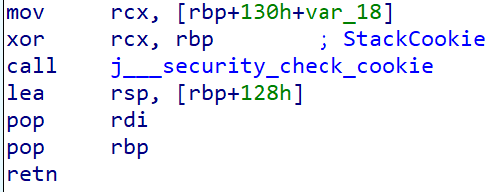
The function call to j__security_check_cookie will verify if rcx is set to 0 or not. If not, then the function will abort the program.
Implementation in Windows kernel
The Windows kernel also provides support for stack canary based protection. However, upon conducting my analysis, I discovered a limited number of functions that incorporate canary check. Furthermore, there is no explicitly defined criteria known regarding the selection of these functions by the kernel. Nevertheless, you will encounter some instances similar to the ones mentioned below:
prolog:

epilog:
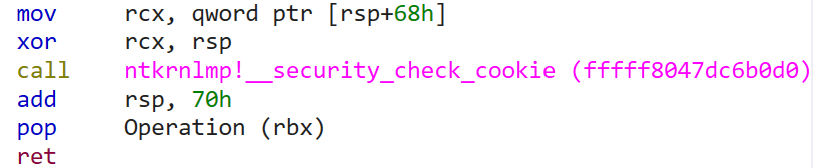
Note that the kernel doesn’t use gs or fs segments to store random canary but rather has a global variable defined for this.
Limitation of stack canary
The most prominent issue with stack canary’s overall architecture is that it's there to detect the overflows rather than protect it. i.e it does not prevent a buffer from overflowing but instead detects the overflow once it has already occurred, during the function return.
Above can be a challenging situation in multiple cases like below:
In kernel space stack guard is not the best solution since the memory mapping in kernel space is linear i.e there is no or very less isolation between different components of kernel. Consequently, if an overflow occurs with the stack guard in place, an attacker can potentially modify other kernel components before the overflow is detected. In summary, if a stack overflow is detected at all on a production system, it is often well after the actual event and after an unknown amount of damage has been done.
Bypassing with brute force:
The success of stack guard heavily depends on the randomization of canary/ guard value. In older or some custom systems, canary values are predefined or pseudo random which makes guessing it easy for the attacker. If the value is guessed correctly, stack canary becomes essentially useless.
LibSafe and Libverify
LIbsafe was an important idea presented on usenix conference by a few researchers from bell labs and rst corp in 2000. It was targeted for the linux platform and was merged into Debian the same year.
Unlike most other common mitigations, libsafe/libverify can work on pre compiled binary as all of its implementation is present as a dynamic loaded library that can be loaded along with any or all processes.
LibSafe
The libsafe intercepts all calls to library functions that are known to be vulnerable from their loaded library. A substitute version of the corresponding function implements the original functionality but in a manner that any buffer overflow are contained within the current stack frame. Detection is based on maximum buffer size that a single write can modify, which get realized by the fact that local buffers cannot be modified beyond the current stack frame. It can be understood more clearly with the below illustration
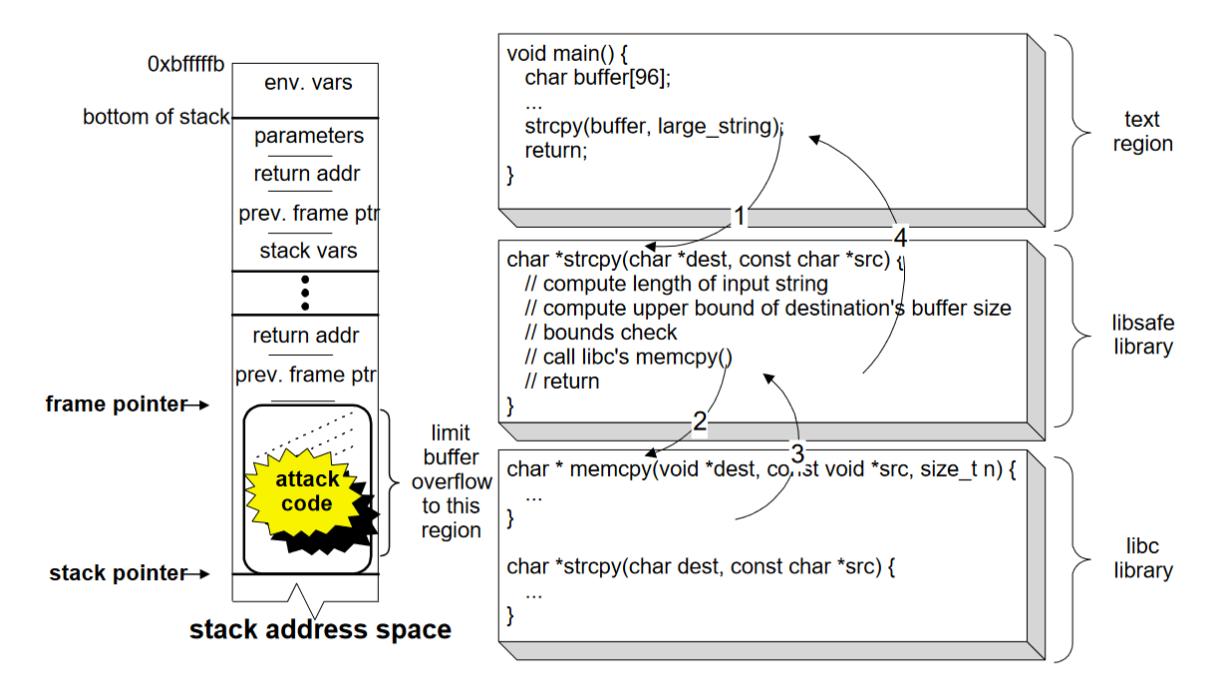
At the time strcpy() is called, the frame pointer (i.e., the ebp register in the Intel Architecture) will be pointing to a memory location containing the previous frame’s frame pointer. Furthermore, the frame pointer separates the stack variables (local to the current function) from the parameters passed to the function. The size of the buffer and all other stack variables residing on the top frame cannot extend beyond the frame pointer—this is a safe upper limit. A correct C program should never explicitly modify any stored frame pointers, nor should it explicitly modify any return addresses (located next to the frame pointers). Libsafe use this knowledge to detect and limit stack buffer overflows. As a result, the attack executed by calling the strcpy() can be detected and terminated before the return address is corrupted.
LibVerify
The libverify library relies on verification of the function's return address before it is used (in a similar way StackGuard is used). It injects the verification code at the start of process execution via rewriting the binary after it is written on the memory. It can be illustrated using the diagram below.
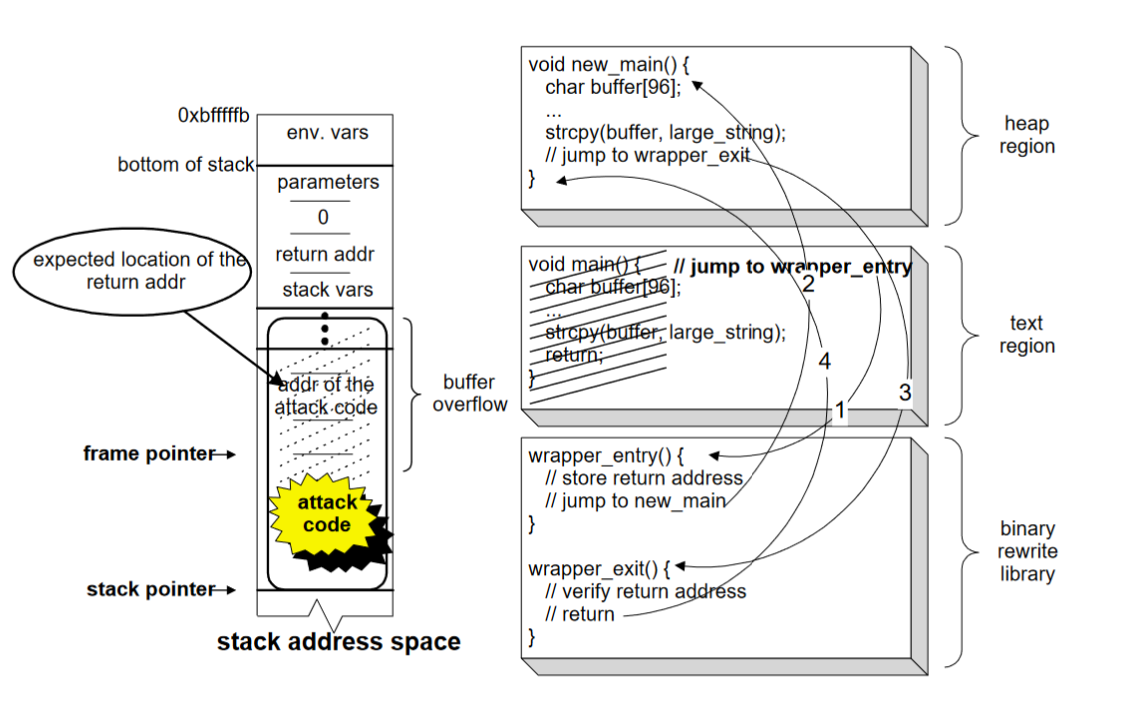
Before the process commences execution, the library is linked with the user code. As part of the linking procedure, the init() function in the library is executed. The init() function contains a stub to instrument the process such that the canary verification code in the library will be called for all functions in the user code.
The instrumentation includes the following steps:
1. Determine the location and size of the user code.
2. Determine the starting addresses of all functions in the user code.
3. For each function (a) Copy the function to heap memory.(b) Overwrite the first instruction of the original function with a jump to the wrapper entry function. (c) Overwrite the return instruction of the copied function with a jump to the wrapper exit function.
The wrapper entry function saves a copy of the canary value on a canary stack and then jumps to the copied function. The wrapper exit function verifies the current canary value with the canary stack. If the canary value is not found on the canary stack, then the function determines that a buffer overflow has occurred. In contrast to StackGuard, which generates random numbers for use as canaries, libverify uses the actual return address as the canary value for each function. This simplifies the binary instrumentation procedure because no additional data is pushed onto the stack, which means that the relative o sets to all data within each stack frame remain the same.
Resources:
StackShield
Stack shield is an independent toolset that was released in 2000 for linux. It consist of shieldgcc and shieldg++ (replacement of default gcc and g++) to compile c/c++ binary with stackshield protection.
Stack Shield has two main protection methods: the Global Ret Stack (default) and the Ret Range Check. The core feature(Global Ret Stack) of stackshield is to save and verify the return address in a separate memory space named retarray.
It uses two global variables for a function. rettop – which stores the end address of retarray and retptr which holds the address where next return address need to be saved. On entry to a protected function, the return address is copied from the stack to retarray and retptr is incremented. During epilog return addresses saved in stack are not used. Instead of them, the cloned return address stored in retarray are honored. The pseudo assembly for stack shield looks like this:

Stack shield also contain another level of protection where the cloned return address is compared with the one presented in stack, and if they are different, a SYS exit system call is issued, abruptly terminating the program.
Another feature of Stack shield Ret Range Checking which detect and stop attempts to return into addresses higher than that of the variable shielddatabase, assumed to mark the base for program’s data, where we may say for simplicity, heap and stack are located. The pseudo code for this looks something like this:

Resources:
Stackshield homepage: https://www.angelfire.com/sk/stackshield/index.html
More info: https://www.cs.purdue.edu/homes/xyzhang/spring07/Papers/defeat-stackguard.pdf
Stackghost
In 2001, Mike Frantzen from Purdue university came up with a Hardware-facilitated stack overflow protection technique that will be implemented on kernel space, named as StackGhost. In 2001 stackghost was added in OpenBSD but started to be shipped enabled by default in 2004. It was one of the major initial research done against protecting stack overflows, that has inspired many researchers and implementation later in future.. The StackGhost research was mostly targeted for Sun microsystems Sparc architecture but can easily be imported to other architectures.
It uses register windows in SPARC architecture to make stack overflow exploitation harder. Stackghost only needs to be evoked on deep function calls and recursive function calls. From the Wikipedia:
It uses a unique hardware feature of the Sun Microsystems SPARC architecture (that being: deferred on-stack in-frame register window spill/fill) to detect modifications of return pointers (a common way for an exploit to hijack execution paths) transparently, automatically protecting all applications without requiring binary or source modifications.
Along with the above main StackGhost idea, this research also suggested additional mechanisms that can be added with the above method to make stack overflow exploitation harder. These ideas were very raw during that time, hence worth to mention here:
Encoded Return address: Rather than saving the exact return address, a reversible transform can be applied to the actual return address and the result saved process stack. When the return address needs to be accessed, the reverse transform can be applied before the access completes. To retrieve the actual value a reverse computation is calculated. If the attacker doesn’t know the transform or the key to transform, he/she will not be able to redirect the program flow with his own shellcode address.
One of the ways above technique can be used is by using the last two LSB in address since they are always zero due to 32 bit word alignment required for each instruction in SPARC architecture. The transformation can invert one or both least significant bits. A corrupted return address will be detected when these bits are not set during inverse transformation.
Return Address stack: A corrupt return pointer can also be detected by keeping a return-address stack. Every time a return pointer is saved to the program stack, the handler can keep another copy in memory not accessible to the userland process (a return-address stack). A corrupt return pointer is detected if a function tries to return to a location not saved in the return stack.
The idea is to have a return address stack as a FIFO queue. A refined approach to designing a return-address stack is to add a small hash table in the PCB. Every time a register window needs to be cleansed, the mechanism would add an entry into the hash table (indexed off the base address of the stack frame). And then store the base address to use as the comparison tag, the return pointer, and a random 32- bit number. In the place of the return address in the stack frame, it would place a copy of the random number. When StackGhost retrieves the stack frame to refill the register window, it can compare the random number on the stack with its image in the hash table. If the instances do not match, an exploit has occurred and the program must be aborted.
XOR Cookie – Another important mention in Stackghost paper is to protect the return address by XORing a fixed cookie with the return address. XORing the cookie before it is saved and xoring again after it popped off preserve the legitimate pointer but distort the attack. Stackghost's idea was to build either a 13 bit preset cookie in OpenBSD kernel that will remain same throughout the system/between processes or have a per process cookie.
Encrypted Stack Frame – Corrupted return can also be detected by encrypting part of the stack frame when the window is written to the stack and decrypting it during retrieval. Although it is going to have a significant performance impact.
Limitations of Stack Ghost
- Randomness of XOR cookie is low, making it easily predicted and align with the actual address.
- Most of the techniques that stackghost use are based on detection but not prevention. An exploit can still cause Denial of service.
- StackGhost will not stop every exploit, nor will it guarantee security. Exploits that StackGhost will not stop include:
- 1. A corrupted function pointer (atexit table, .dtors, etc.)
- 2. Data corruption leading to further insecure conditions.
- 3. “Somehow” overwriting a frame pointer with a frame pointer from far shallower in the calling sequence. It will short circuit backwards through a functions’ callers and may skip vital security checks.
Execution space protection
A process or kernel memory is partitioned into several segments that serve different purposes. For example, a process memory typically consists of a executable section (.text), read only data (.rodata), read/writable data (.data), a stack and a heap. Below is one way of memory layout
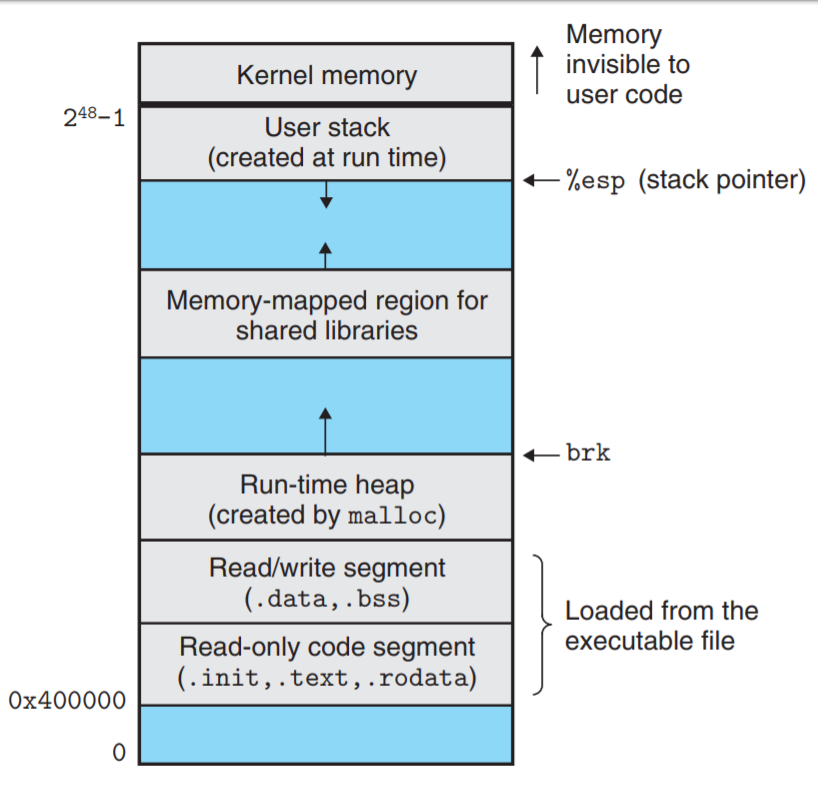
Since each section has different usage, they required different memory permissions. For instance, by default, the .rodata section should exclusively possess read permissions, while the .text section should possess both read and execute permissions.
It is imperative for operating systems to effectively enforce these permissions in order to circumvent unexpected behavior or misuse of memory. For instance, there may exist scenarios wherein an attacker gains the privilege to write to any memory location within a process. This privilege can be exploited by modifying the program's behavior through altering the instructions within the text section of the process's memory. However, with accurately enforced memory permissions, any attempts to write to the text section of the process's memory will be thwarted.
Note: You can check the memory permissions of each section for a process in linux by using cat /proc/<pid>/maps. Similarly the process memory permissions can be checked in windows using !address command in windbg attached to the target process.As a part of ESP, your loader will mark the memory region as Non executable to block execution of any shellcode in that area. In a perfectly implemented operating system, following memory regions are marked as non executable:
- All non writable sections including .data, .rodata, .bss etc
- Stack and heap of process
The above implementation will prevent any exploitation of process address space against any arbitrary shellcode execution present in these memory regions. To make this execution prevention more readily implementable, chipmakers have implemented this as a hardware feature called as Data Execution prevention/NX stack explained below:
NX protection
In 1998, a team name “solar designers” developed a patch for linux that will make the stack non executable. But due to the gcc’s limitations of using stack to store trampoline function and executing it, the implementation didn't get merged in gcc until 2004 (which was after the introduction of NX bit in x86 processors).
Intel and AMD introduced NX bit support in 2001 in AMD64 and Intel Itanium processors respectively. This is an extra bit added in the page table entry to mark the page as non executable.
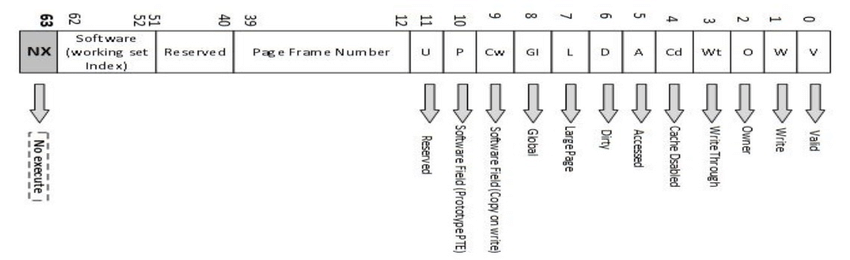
In 64 bit machine (as mentioned in above image) the bit 63rd (MSB in address) will be used to mark a page as non executable. This will prevent the impact of buffer overflow exploitation where attacker try to execute shellcode present in the user input buffer in stack or heap.
This feature was introduced in windows with the name DEP (Data execution prevention) in 2003 in windows XP. Currently, NX protection is available and used at all major operating systems at userspace and kernel space both.
Limitations of NX stack
Clearly the protection will only protect against the case where an attacker will try to pass the shellcode in user buffer and execute it later. The return address redirection is still possible. Attackers can still redirect the program flow to a function already present inside process memory. One such famous attack in linux is “return to libc”. This method is also called ROP or JOP (where ROP stands for Return oriented programming and JOP for Jump oriented programming).
Resources:
https://academickids.com/encyclopedia/index.php/NX_bit
Propolice
Propolice is the stack smashing protection patches that are added by IBM in gcc in year 2004. The idea was based on improving the coverage and detection of existing Stack Guard protection.
The improvement in propolice method compared to stackguard is the location of the guard and the protection of function pointers. The guard is inserted next to the previous frame pointer and it is prior to an array, which is the location where an attack can begin to destroy the stack.
The Propolice extension patch consists of following major changes to existing gcc:
- the reordering of local variables to place buffers after pointers to avoid the corruption of pointers that could be used to further corrupt arbitrary memory locations,
- the copying of pointers in function arguments to an area preceding local variable buffers to prevent the corruption of pointers that could be used to further corrupt arbitrary memory locations, and the
- omission of instrumentation code from some functions to decrease the performance overhead.
Safety function model:
To decrease the impact of stack overflow, propolice includes an improved function stack model compared to stackguard, that can be followed to minimize the impact of stack overflow.
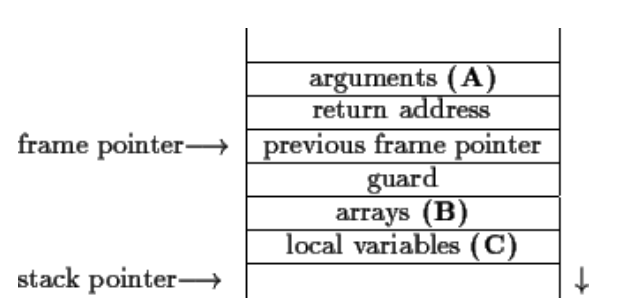
safety function model, which involves a limitation of stack usage in the following manner:
- the location (A) has no array or pointer variable
- the location (B) has arrays or structures that contains an array
- the location (C) has no array
This model has the following properties:
- The memory locations outside of a function frame cannot be damaged when the function returns.
- The location (B) is the only vulnerable location where an attack can begin to destroy the stack. Damage outside of the function frame can be detected by the verification of the guard value. If damage occurs outside of the frame, the program execution stops.
- An attack on pointer variables outside of a function frame will not succeed. The attack could only succeed if the following conditions were satisfied: (1) the attacker changes the value of the function pointer, and (2) he calls a function using the function pointer. In order to achieve the second condition, the function pointer must be visible from the function, but our assumption says this information is beyond the function scope. Therefore, the second condition can't be satisfied, and the attack will always fail.
- An attack on pointer variables in a function frame will not succeed. The location (B) is the only vulnerable location for a stack-smashing attack, and the damage goes away from area (C). Therefore, the area (C) is safe from the attack.
Pointer protection
Another common stack overflow exploitation scenario is when the vulnerable function consists of a function pointer as local variable like below:

In order to protect function pointers from stack-smashing attacks, propolice change the stack location of each variables to be consistent with the safe function model. It makes a new local variable, copying the argument func1 to it, and changing the reference to func1 to use the new local variable.

The propolice methodology is still used by gcc and other compilers to a greater extent.
Resources
https://web.archive.org/web/20040603202721/http://www.research.ibm.com/trl/projects/security/ssp/
https://dominoweb.draco.res.ibm.com/reports/rt0371.pdf
Honorable mention:
In windows 10, Microsoft has added a new mitigation named Arbitrary code guard in Windows kernel, which is based on setting and verifying memory permissions for specific pages based on certain policy and blocking the attempt that breaks the policy. ACG is based on prevents a process from doing these two things:
- Allocating new executable memory (without an image file backing it)
- Modifying any existing executable memory by writing to it.
You can read more about ACG here: https://blogs.windows.com/msedgedev/2017/02/23/mitigating-arbitrary-native-code-execution/
ASLR (Address Space Layout Randomization)
The idea of ASLR was first introduced in PAX project in 2001. Later it was added in OpenBSD in 2003, followed by linux in 2005 and Windows vista in 2007. The main goal of ASLR is to prevent the exploitation due to memory corruption rather than the detecting/preventing corruption itself.
The exploitation of a memory corruption vulnerability entails the act of redirecting the return address to an alternative function or shellcode address that is either malicious or unexpected. In order for the exploitation to be successful, the attacker must possess knowledge of the specific target address that they intend to execute. Drawing inspiration from this, Address Space Layout Randomization (ASLR) was implemented as a means to randomize the addresses of most, if not all, sections within a process's memory. By doing so, this serves to prevent attackers from being able to predict the location of any malicious function or shellcode addresses.
ASLR in action
ASLR in linux
Let’s take a look at simple c program below to understand the impact of ASLR:
When you execute the below code multiple times in linux, you will get the output like below:
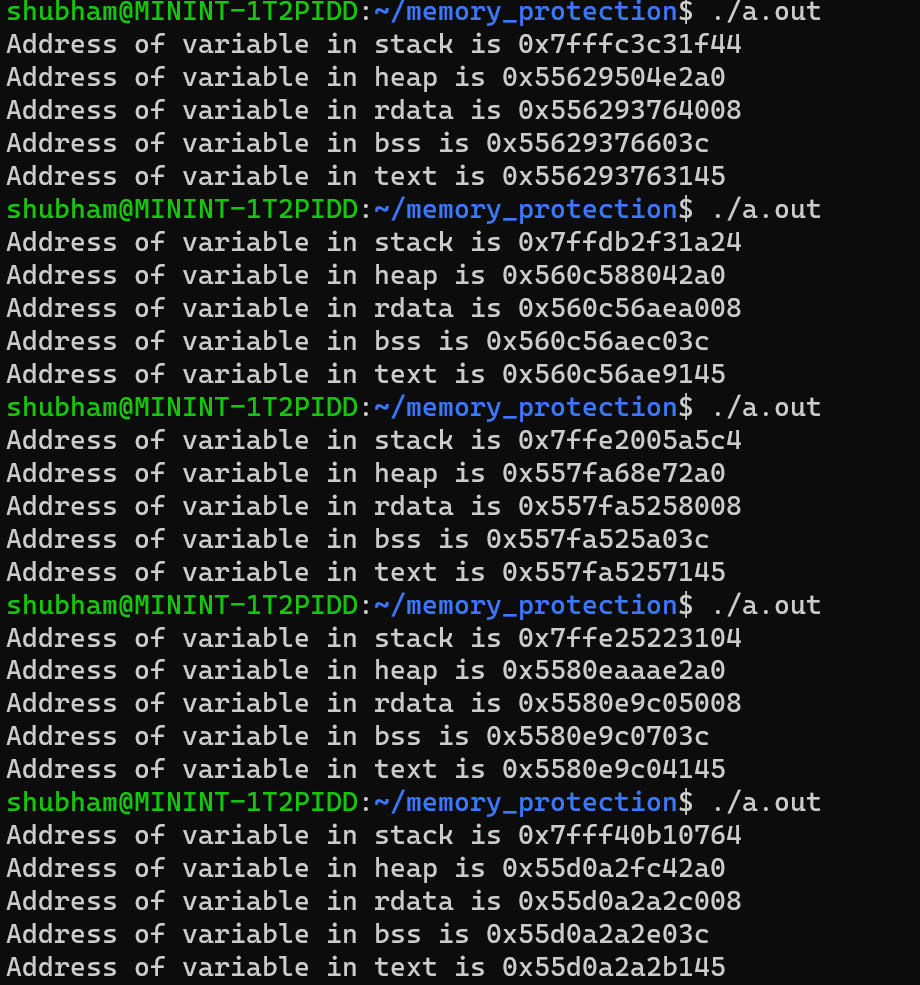
From the above output, we can conclude that linux have following memory layout:

Although the order of the various sections remains consistent, the different addresses of variables during each execution imply that the base address for each section changes. However, it is worth noting that the text section possesses a fixed address. Due to this element of randomization, accurately determining the location of certain data or shellcode in the process memory becomes exceedingly challenging, thereby making it difficult for an attacker to exploit the buffer overflow scenario for the purpose of executing a shellcode.
ASLR in linux kernel (KASLR)
Linux kernel added support for ASLR in 2006 (v2.6) which known as KASLR – Kernel address space layout randomization. KASLR patches has introduced following changes in kernel memory:
- Kernel image which used to reside at a static address in lowmem can now be present at any memory location in kernel memory.
- Initial loading addresses of modules are randomized.
- Both virtual and physical addresses of components get randomized.
- Other memory regions like vmalloc, vmap and ioremap area are also randomized.
- Later the linux kernel also introduced the KSTACK_RANDOMIZE feature that will randomize the kernel stack base created on each syscall.
Let’s verify the impact of KASLR in linux kernel:
You need to load the below compiled driver to understand the effect of KASLR in linux kernel:
Below is the dmesg output:
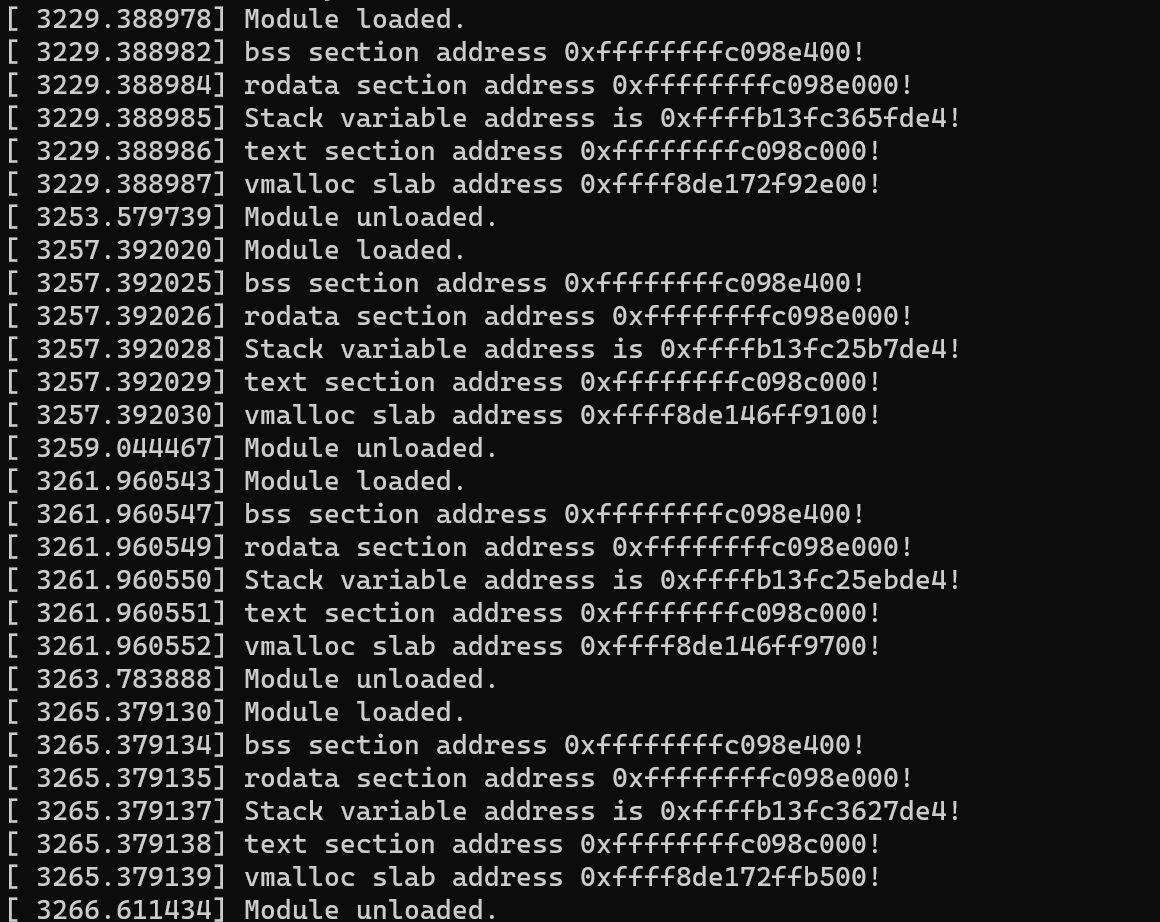
You will notice that only the stack and heap is randomized. Other sections like .rodata and .text are not randomized since the module is loaded unloaded frequently, hence getting the same address each loading. But on reboot, you will notice the different address assign to those as well.
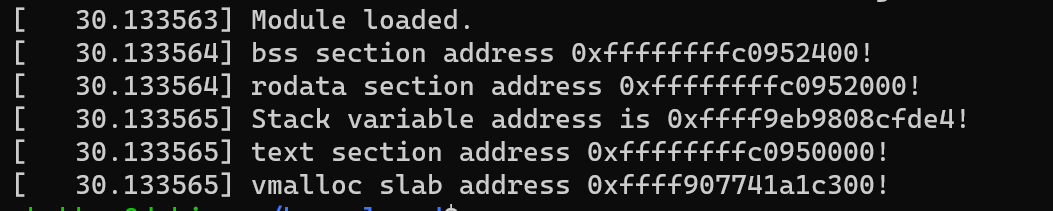
Other observation you will notice for KASLR is that the randomization of address is very less. Only the base addresses of sections are changing but the offsets are pretty much the same.
ASLR in windows
Let’s compile the above program in Visual Studio 2022 in windows 11 and verify the output:
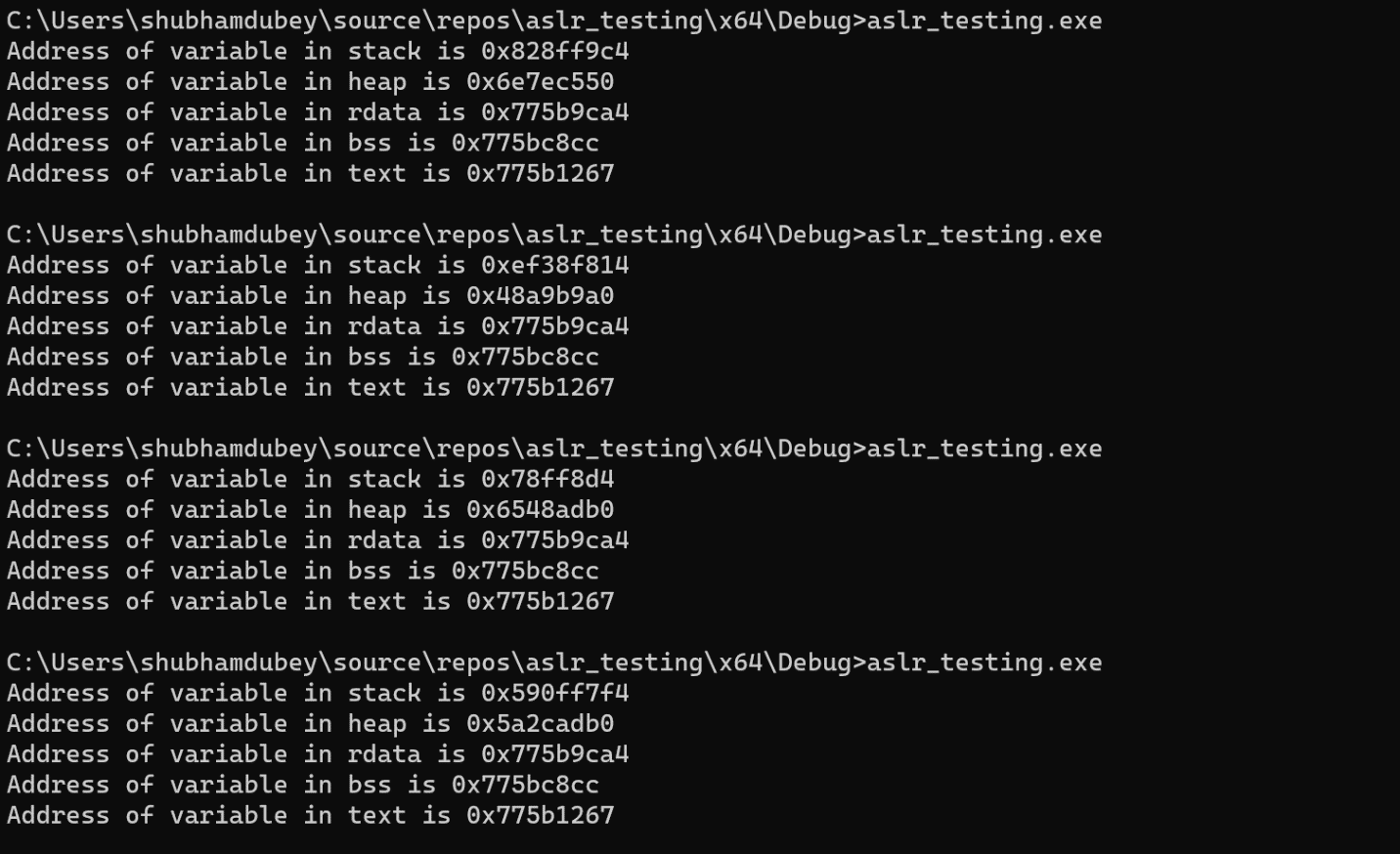
One may observe that, in addition to the heap and stack, all other variables are located at a fixed address. This suggests that the design of Windows Address Space Layout Randomization (ASLR) takes into consideration the fact that the majority of buffer overflow exploits involve shellcode in the heap and stack, thus necessitating randomization. In order to minimize the overhead of randomization, it is not applied to the remaining sections of the process memory.
We will skip the part of verifying ASLR in windows kernel for now but it can be easily looked with windbg !address extension used with kernel debugger attached.
Limitation of ASLR
Address brute force due to Low entropy
The quality of mitigation provided by ASLR depends on the randomization of the different address spaces in process memory. ASLR is implemented in almost all types of operating systems but has different levels of randomization for different address spaces. Even from the above ASLR POCs, you will notice that the randomization level in windows is quite low compared to linux. Due to less randomization, it became very easy for attackers to guess the address where shellcode or gadgets reside. Moreover, most ASLR implementations have only a few bytes to randomize and keep base address or certain MSB bytes same.
You can easily look for lots of writeups and project to bypass ASLR by bruteforcing the address.
Having a module loaded with no ASLR support
In the Linux operating system, the binaries are constructed by default with the -fPIC compiler option in gcc. This particular option indicates that the resulting code will possess the necessary functionalities to enable relocation. This is an essential prerequisite for Address Space Layout Randomization (ASLR) to be operational within the binaries' address space. In the event that the binary is not compiled with this option, or if it is explicitly stated that the binary or library does not support relocation, different addresses of different sections at which the binary or library is loaded into memory will remain consistent on each execution.
Sometimes when a binary itself is fully ASLR compatible, it may have a module/dll loaded that doesn’t support the randomization. In those cases, an attacker can try to find ROP gadgets in that unsupported ASLR binary for successful shellcode execution.
Memory address leak
The primary adversary encountered by any ASLR implementation is the exposure of addresses to the user. It can be understood using below case:
In the above program, there exists an overflow in the username variable, which provides attackers with the opportunity to inject shellcode into the username data and subsequently execute it. However, the presence of Address Space Layout Randomization (ASLR) should ideally make it difficult to guess the address of the shellcode. Nevertheless, the program also exhibits a format string vulnerability due to the utilization of printf(buffer), which, if correctly formatted (e.g., by passing %p%p%p... as the input on the first prompt), will disclose the address of the username buffer. Upon receiving these leaked addresses, an attacker can modify the payload in the second prompt in order to successfully redirect the return address to the shellcode. This entire configuration renders the randomization of the stack meaningless.
On similar ground, Address leak is a major culprit of KASLR bypasses in kernel space in windows and linux.
Heap spraying to bypass ASLR
The idea behind this technique is to make multiple addresses lead to the shellcode by filling the memory of the application with lots of copies of it, which will lead to its execution with a very high probability. The main problem here is guaranteeing that these addresses point to the start of it and not to the middle. This can be achieved by having a huge amount of nop bytes (called NOP slide, NOP sled, or NOP ramp), or any instructions that don't have any major effect, such as xor ecx, ecx:
During exploitation of a security issue, the application code can often be made to read an address from an arbitrary location in memory. This address is then used by the code as the address of a function to execute. If the exploit can force the application to read this address from the sprayed heap, it can control the flow of execution when the code uses that address as a function pointer and redirects it to the sprayed heap. If the exploit succeeds in redirecting control flow to the sprayed heap, the bytes there will be executed, allowing the exploit to perform whatever actions the attacker wants. The whole concept will work even on the presence of ASLR.
Using Sidechannel to break ASLR
There are multiple researchers published since 2016 that focus on bypassing ASLR or guessing target address space using sidechannel attacks. One such research named “Jump over ASLR” published in 2016, uses BTB buffer to bypass ASLR randomization in userspace or kernel space. Below is few key points from the research.
This new attack can recover all random bits of the kernel addresses and reduce the entropy of user-level randomization by using side-channel information from the Branch Target Buffer (BTB). The key insight that makes the new BTB-based side-channel possible is that the BTB collisions between two user-level processes, and between a user process and the kernel, can be created by the attacker in a controlled and robust manner. The collisions can be easily detected by the attacker because they impact the timing of the attacker-controlled code. Identifying the BTB collisions allows the attacker to determine the exact locations of known branch instructions in the code segment of the kernel or of the victim process, thus disclosing the ASLR offset.
The attacks exploit two types of collisions in the BTB. The first collision type, exploited to bypass KASLR, is between a user-level branch and a kernel-level branch - they call it cross- domain collisions, or CDC. CDC occurs because these two branches, located at different virtual addresses, can map to the same entry in the BTB with the same target address. The reason is that the BTB addressing schemes in recent processors ignore the upper-order bits of the address, thus trading off some performance for lower design complexity. The second type of BTB collisions is between two user-level branches that belong to two different applications. They call these collisions same-domain collisions, or SDC. SDCs are used to attack user-level ASLR, allowing one process to identify the ASLR offset used in another. An SDC occurs when two branches, one in each process, have the same virtual address and the same target.
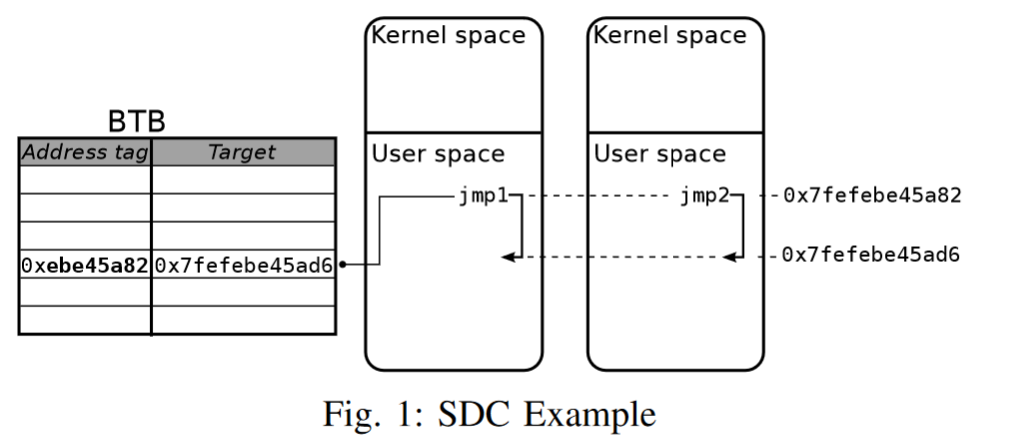
You can read more detail about the research here: https://www.cs.ucr.edu/~nael/pubs/micro16.pdf
Blindside Attack
Blindside attack discovered by few researchers from Stevens Institute of Technology in New Jersey, ETH Zurich, and the Vrije University in Amsterdam. in 2020 (2 years after Specter, Meltdown surfaced) used Speculative execution modern processor feature to Bypass KASLR. The goal of blindside research was to make KASLR brute forcing (probing) more significant and faster.
When performing probing to bypass KASLR, the non crash resistance nature of linux kernel makes KASLR probing mere a concept. Using speculative execution processor feature for crash suppression allows the elevation of basic memory write vulnerabilities into powerful speculative probing primitives that leak through microarchitectural side effects. Such primitives can repeatedly probe victim memory and break strong randomization schemes without crashes and bypass all deployed mitigations against Spectre like attacks. The key idea behind speculative probing is to break Spectre mitigations using memory corruption and resurrect Spectre style disclosure primitives to mount practical blind software exploits. This became possible since crashes and the probe execution in general are suppressed on speculative paths. You can read about the research here https://download.vusec.net/papers/blindside_ccs20.pdf
KASLR information leak mitigation – kptr_restrict and dmesg_restrict
Kaslr was implemented into the Linux kernel in the year 2006. Since its implementation, various methods have been developed to circumvent kaslr, thereby introducing vulnerabilities into the Linux kernel. These bypasses primarily occur due to the presence of information leaks. These leaks can manifest as either pointer leaks, such as leaks of pointers to structs or heap/stack areas, or content leaks. Illustrative examples of associated CVEs include CVE-2019-10639 (Remote kernel pointer leak), CVE-2017- 14954.
To minimize the impact of address leak linux kernel has added features kptr_restrict and dmesg_restrict.
ptr_restrict - This indicates whether restrictions are placed on exposing kernel addresses via /proc and other interfaces. When kptr_restrict is set to (1), kernel pointers printed using the %pK format specifier will be replaced with 0’s unless the user has CAP_SYSLOG.
dmesg_restrict - This indicates whether unprivileged users are prevented from using dmesg to view messages from the kernel's log buffer. When dmesg_restrict is set, users must have CAP_SYSLOG to use dmesg.
The FGKASLR – Fine gained KASLR
Added in linux kernel in 2020, FGKASLR is a replacement of existing KASLR in linux to improve KASLR capability against code reuse attack. Here are few details about FGKASLR from their commit detail:
KASLR was merged into the kernel with the objective of increasing the difficulty of code reuse attacks. Code reuse attacks reused existing code snippets to get around existing memory protections. They exploit software bugs which expose addresses of useful code snippets to control the flow of execution for their own nefarious purposes. KASLR moves the entire kernel code text as a unit at boot time in order to make addresses less predictable. The order of the code within the segment is unchanged - only the base address is shifted. There are a few shortcomings to this algorithm.
1. Low Entropy - there are only so many locations the kernel can fit in. This means an attacker could guess without too much trouble.
2. Knowledge of a single address can reveal the offset of the base address, exposing all other locations for a published/known kernel image.
3. Info leaks abound.
Finer grained ASLR has been proposed as a way to make ASLR more resistant to info leaks. It is not a new concept at all, and there are many variations possible. Function reordering is an implementation of finer grained ASLR which randomizes the layout of an address space on a function level granularity.
That's all about first generation mitigations. We will go through the second generation in next section.






